
You can connect directly to your data and run SQL queries on your events and users stored in the deltaDNA data warehouse. You should be able to connect using any Postgres ODBC compliant tools.
Get Connected
-
Some tools will come with their own built in Postgres ODBC driver, others may require you to download a driver and set-up a connection (DSN) before you can use them. The applications below marked with ♦ will require you to do this.
Check out our Postgres ODBC Connection Guide for details on how to do this.
- Connect to your data using your favoured database manager. The following links show how to connect to your data using the following tools.
-
- DBeaver : A Free Universal Database Manager
- OpenOffice: A Free suite of office tools
- Microsoft Excel ♦ : Microsoft’s flagship spreadsheet software
- Tableau ♦ : Data visualisation tools
- R : Statistical computing and graphics programming language
Data Tables
There are three types of data that can be accessed, in each case you have separate tables for your DEV and LIVE environments.
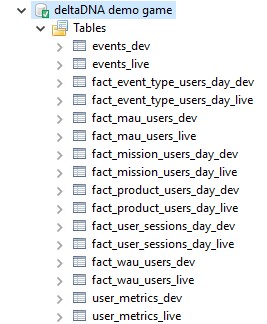
- Raw Event Data: This is raw event data containing all the events and parameters for your most recent events as determined by the data retention policy on your game, typically 365 days.
Tables : events_dev and events_live - User Metrics Data. The user metrics table contains a row of data for every player in your game, regardless of how long ago they last played. Numerous metrics that are automatically tracked and added to this table for each user but you can also define which of your event parameters are tracked as metrics in the Game Parameters Manager tool. Engage Campaigns and A/B Tests access a real-time version of this data when running player segmentation queries, the user metrics that you access through direct access are a daily snapshot of the last known state for every player, updated overnight every 24 hours.
Tables: user_metrics_dev and user_metrics_live - Aggregated Measure Chart Data : The remaining tables, prefixed with fact contain the aggregated data that is used to drive many of the Measure Dashboard Charts. So, you can run queries on aggregated data covering the entire history of your game.
Tables: Six tables for each environment, prefixed with fact_ covering events, mau, wau, sessions, missions and products
Know Your Data
You will get much more from your data if you are familiar with the events and parameters that you are sending and how it is stored.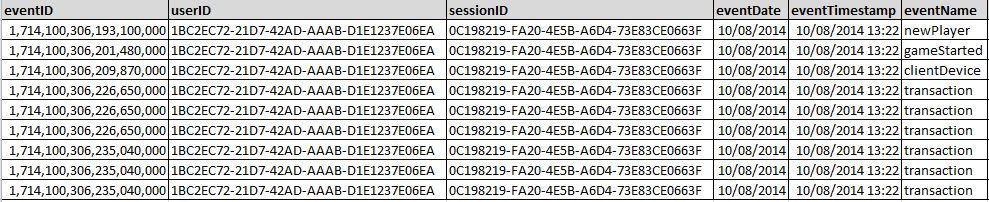
- Your events can be viewed and edited in the Event Management Tool. It is recommended that you familiarise yourself with the events that your game is sending. It can also be useful to use the Event Browser QA Tool to watch events as they arrive.
- The event table structure is very simple, your events are stored in a wide table with a column for each parameter that you have configured in the Game Parameters tool and at least one row for each event. Complex events can span multiple rows. When you use the data mining tool or download any of your daily event archive files you will be accessing data in this wide table format.
There are a few things worth mentioning about your events data.
- Empty columns : As there is a column for every parameter that has been configured on your game, there will be many columns with no data on any given row as the parameter wasn’t relevant to the particular event.
- Additional columns : You will spot some additional columns that the platform has automatically added. The majority of these are prefixed with GA and come from the user_metrics.

- eventLevel : The example below shows 9 rows, but there are actually only 5 events here. The transaction events that you see are actually just two events, each with two nested child objects that were sent in an array. Use the eventLevel and mainEventID parameters to understand the parent/child relationships on nested events.
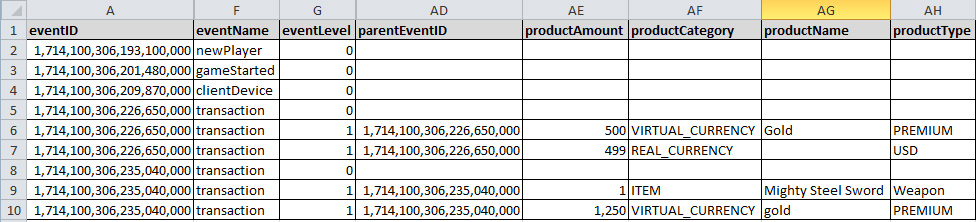
- convertedProductAmount : When you add a game to the platform you nominate a currency that you want your dashboards to display your revenue in. The productAmount and productType columns will always contain the local currency that was spent by the player and the convertedProductAmount column will contain the value converted to your nominated currency at the time of purchase.
- revenueValidated : The revenueValidated flag shows the status of revenue validation requests with the App Store if you are using this deltaDNA feature. The values you will see are:
- 0 : not validation undertaken
- 1 : revenue valid
- 2 : revenue invalid
- 3 : error during validation
You can download the example events above if you want to take a look at some of the other columns / parmaters from this example game.
SQL Cookbook
Considerations
When running queries against your data, there are a few things to take into consideration.
Important: Be careful with SELECT *
- It is always far more efficient to specify which columns you are interested in a column store like Snowflake rather than using SELECT * . If you specify the column names your queries will run much more quickly.
- Conversely, if you are counting columns, you should always use a COUNT(*) as this will let Snowflake to choose the best column to do the count
- Your events table stores all events from the last 365 days by default, this can be extended. Please contact [email protected] for more info
- The events table contains a column for each parameter in your game parameters list as well as some automatically populated columns
- Events that contain arrays or nested objects will appear as multiple rows in you events table. The eventLevel (0 or 1) and mainEventID columns are used to link parent and child events together, e.g. the transaction event
- The users table contains a one row for each user in your game. The effective_date column holds a record of when the user metric was last updated
- You cannot perform potentially destructive SQL commands on your data
- The deltaDNA PostgreSQL Driver should be used for running ad hoc analytics queries and reports. It shouldn’t be used to download data extracts, your daily data archives stored on Amazon S3 are better suited to this. A limit of 10MB has been placed on SQL data transfers to prevent the SQL driver being misused. Your query will fail and return the following error message if it exceeds the transfer limit, “ResultSet has exceeded maximum query data transfer.”
- Any SQL queries running for longer than 30 minutes will be automatically terminated. If you have a particular query that is running for too long, let us know, as we may be able to advise on optimisations to your SQL that will make it run more quickly. We do monitor the analytics database and scale the cluster to accommodate the data volumes and usage.
- Your data is stored in a Snowflake data warehouse. You will find a reference manual for the SQL functions it supports in the Snowflake SQL Function Reference Manual
- You cannot use any of the following reserved words in your SQL queries:
|
1 |
all_tables, columns, comments, constraint_columns, databases, dual, elastic_cluster, epochs, fault_groups, foreign_keys, grants, license_audits, nodes, odbc_columns, passwords, primary_keys, profile_parameters, profiles, projection_checkpoint_epochs, projection_columns, projection_delete_concerns, projections, resource_pool_defaults, resource_pools, roles, schemata, sequences, storage_locations, system_columns, system_tables, table_constraints, tables, types, user_audits, user_functions, user_procedures, user_transforms, users, view_columns, views, active_events, column_storage, configuration_changes, configuration_parameters, cpu_usage, critical_hosts, critical_nodes, current_session, data_collector, database_backups, database_connections, database_snapshots, delete_vectors, deploy_status, design_status, disk_resource_rejections, disk_storage, error_messages, event_configurations, execution_engine_profiles, host_resources, io_usage, load_streams, lock_usage, locks, login_failures, memory_usage, monitoring_events, network_interfaces, network_usage, node_resources, node_states, partition_reorganize_errors, partition_status, partitions, process_signals, projection_recoveries, projection_refreshes, projection_storage, projection_usage, query_events, query_metrics, query_plan_profiles, query_profiles, query_requests, rebalance_projection_status, rebalance_table_status, recovery_status, resource_acquisitions, resource_pool_status, resource_queues, resource_rejection_details, resource_rejections, resource_usage, session_profiles, sessions, storage_containers, storage_policies, storage_tiers, storage_usage, strata, strata_structures, system, system_resource_usage, system_services, system_sessions, transactions, tuning_recommendations, tuple_mover_operations, udx_fenced_processes, user_libraries, user_library_manifest, user_sessions, wos_container_storage, current_database, current_schema, current_user, dbname, has_table_privilege, session_user |
- It is also important to note that there are a number of limited and reserved keyword from Snowflake. These cannot be used as column titles or CTE reference names

